Architecture
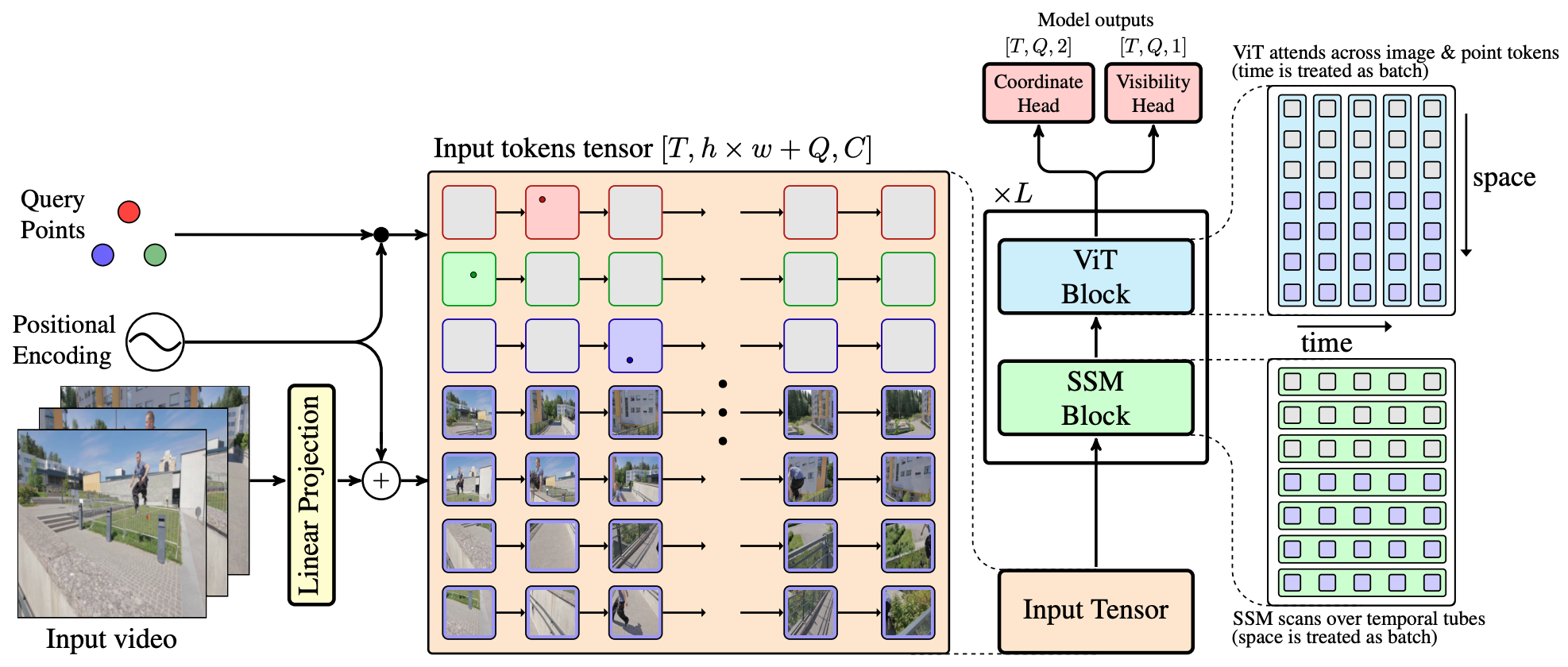
TAPNext redefines point tracking as a sequence of masked token prediction task. Our approach is inspired by modern language models, treating point trajectories in video as sequences of tokens.
Tracking Any Point (TAP) in a video is a challenging computer vision problem with many demonstrated applications in robotics, video editing, and 3D reconstruction. Existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics, limiting their generality and potential for scaling. To address these challenges, we present TAPNext, a new approach that casts TAP as sequential masked token decoding. Our model is causal, tracks in a purely online fashion, and removes tracking-specific inductive biases. This enables TAPNext to run with minimal latency, and removes the temporal windowing required by many existing state of art trackers. Despite its simplicity, TAPNext achieves a new state-of-the-art tracking performance among both online and offline trackers. Finally, we present evidence that many widely used tracking heuristics emerge naturally in TAPNext through end-to-end training.
TAPNext redefines point tracking as a sequence of masked token prediction task. Our approach is inspired by modern language models, treating point trajectories in video as sequences of tokens.
The TAP-Vid benchmark is a set of real and synthetic videos annotated with point tracks. The metric, Average Jaccard, measures both accuracy in estimating position and occlusion. Higher is better.
Method |
DAVIS |
Kinetics |
|---|---|---|
BootsTAP |
62.4 |
55.8 |
TAPTRv3 |
63.2 |
54.5 |
CoTracker3 |
63.8 |
55.8 |
TAPNext |
65.2 |
57.3 |
Benchmarking results show that TAPNext delivers ultra-fast real-time inference, efficiently tracking 1,024 query points with minimal latency.
# Query Points |
Latency, ms (H100) |
Latency, ms (V100) |
|---|---|---|
256 |
5.05 |
14.2 |
512 |
5.26 |
18 |
1024 |
5.33 |
23 |
We visualize TAPNext, Cotracker3, and BootsTAPIR on the DAVIS dataset. We find TAPNext's superior performance in tracking accuracy and robustness, particularly in handling for nonrigid, dynamic and rapid motion. Pay Attention to the tracking on the foreground objects.
| BootsTAPIR | Cotracker3 | TAPNext |
We visualize the feature maps of video tokens from the final layer of the TAPNext model using Principal Component Analysis (PCA). To demonstrate the model's capabilities, we applied it to a camouflage video sequence and visualized its final layer feature representations. Remarkably, when processing the video sequence, the model successfully discovered the camouflaged animal purely based on motion cues, showcasing its exceptional ability to group tokens based on motion.

|

|

|

|

|

|

|

|

|
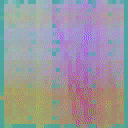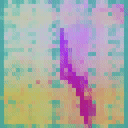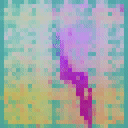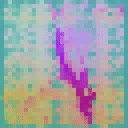
|

|

|
Here we visualize TAPNext on more videos from DAVIS and RoboTAP dataset.
We visualize self-attention maps between point tokens and image patches, or between point tokens themselves. Higher attention weights are shown with more solid connections between tokens. In the right-hand video, notice how motion segmentation naturally emerges from the online point tracking process at the beginning of the sequence.
Image to Point Attention |
Point to Point Attention |
We invert the traditional tracking problem: instead of predicting point trajectories, we provide the model with the full sequence of points and their occlusion flags, and task it with predicting future pixel values. As described in the paper, this is achieved by adding a simple linear pixel decoder head on top of the TAPNext image token outputs. Note that this is not a generative model—it is trained using a straightforward L2 pixel regression loss. This result highlights TAPNext's ability to store and retrieve visual information effectively.
TAPNext has clear limitations. In particular, we observe significant failures in long-term point tracking when the number of video frames exceeds 150. This limitation is likely due to the state-space models being trained on sequences of at most 48 frames, making it difficult for them to generalize to much longer video clips. However, this also presents an opportunity for substantial improvement—addressing the long-term tracking challenge could lead to significant performance gains.
|
|
Our work is closely related to the following research:
TRecViT - A Recurrent Video Transformer.
BootsTAP - Bootstrapped Training for Tracking-Any-Point.
CoTracker3 - Simpler and Better Point Tracking by Pseudo-Labelling Real Videos.
TAPTR - Track Any Point TRansformers.